
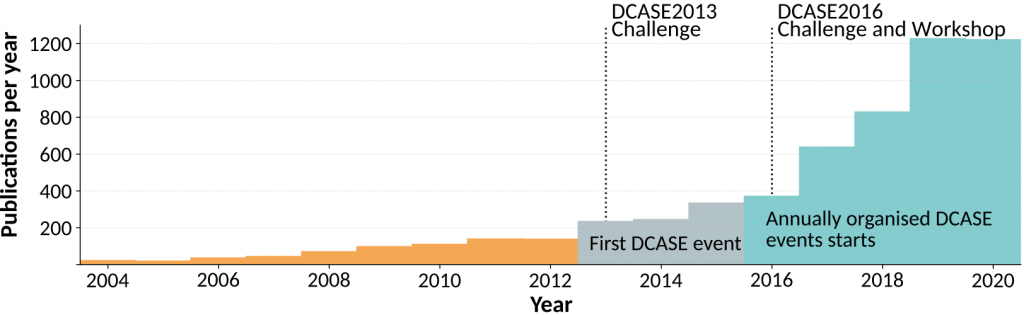
A good example of the impact of the DCASE community can be seen in the number of publications related to sound event detection published per year, shown in the Figure below (data collected from Google Scholar). The first DCASE Challenge was organized in 2013, and after the DCASE events were organized annually in 2016, the publication count has increased steadily from 350 to over 1200 per year.
The core idea of the community is to support the development of audio content analysis methods by providing public datasets and the opportunity to continuously compare different approaches with consistent performance measures in uniform setups. The DCASE Challenge steers the research domain towards open data and reproducibility by establishing standards for evaluation protocols, open-source metric implementations, and open benchmark datasets. These factors support the growth of the research community and have made the DCASE related research attractive also for researchers coming from neighboring research fields.
![]()
The DCASE2021 challenge presented six analysis tasks, each of these tasks focusing on a single target application and research question. The challenge attracted a high number of participants from academic and industrial research teams: the challenge received 394 submission entries from 127 teams to six challenge tasks.
TAU organized three tasks: one related to acoustic scene classification, one related to simultaneous sound event localization and detection, and one related to automated audio captioning. All these tasks are very much related to the audio AI tools used in the MARVEL project.
The first subtask (subtask A) focused on low-complexity solutions that are also able to handle data from various devices, and the second subtask (subtask B) focused on a new research task in DCASE, audio-visual scene classification.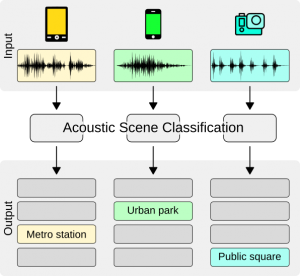
In subtask A, the research question studied was the ASC system’s generalization properties across several different devices, and the solutions were directed towards low-complexity systems by restricting the size of the acoustic model to be under 128KB (only non-zero parameter values counted in). This subtask merged ASC subtasks from the previous 2020 challenge, one studying only generalization properties and one imposing low-complexity, into a setup close to the real ASC use case. For the system development, the participants were provided 64 hours of labelled audio material from real and simulated devices, split into 10-second audio segments; the challenge evaluation was done on 22 hours of unlabeled audio. The used dataset was collected in 12 European cities in a wide range of locations, using multiple different mobile audio capturing devices. The subtask received 99 system submissions from 30 international research teams, and the overall results showed over 70% classification accuracy for 10 scene classes. The top teams utilized model parameter quantization, knowledge distillation techniques, specific neural network architectures, and data augmentation techniques to produce robust classifiers under the given model size restrictions. When compared to the results from DCASE2020 Challenge subtask A with a similar setup but with no imposed model size restriction, the results are very well comparable (76.5% versus 76.1%) while the complexity of the model is considerably lower (36M parameters versus 630K parameters). Detailed results can be viewed on the task results page at the DCASE website and in [1].
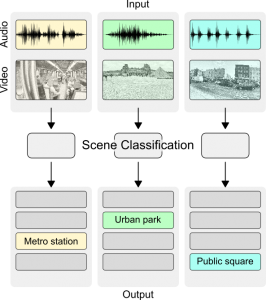 In subtask B, the research question studied was scene classification using audio and video modalities. Audio-visual machine learning has gained popularity in recent years, and the DCASE Challenge provided this multidisciplinary task to provide a common benchmarking setup. In this task, the scene classification decision was done based on a 1-second audio and video segment. Participants were allowed to submit unimodal systems (systems using only audio or video) as well to study the effectiveness of the multimodal approaches. For system development, a 34-hour labelled audio-visual dataset was provided and the challenge evaluation was done on 20 hours of unlabeled audio-visual data.
In subtask B, the research question studied was scene classification using audio and video modalities. Audio-visual machine learning has gained popularity in recent years, and the DCASE Challenge provided this multidisciplinary task to provide a common benchmarking setup. In this task, the scene classification decision was done based on a 1-second audio and video segment. Participants were allowed to submit unimodal systems (systems using only audio or video) as well to study the effectiveness of the multimodal approaches. For system development, a 34-hour labelled audio-visual dataset was provided and the challenge evaluation was done on 20 hours of unlabeled audio-visual data.
The subtask received 43 system submissions from 13 international research teams, and the overall results showed over 93% classification accuracy for 10 scene classes. Multimodal approaches were the best performing compared to unimodal methods. Detailed results can be viewed on the task results page at the DCASE website and in [2].
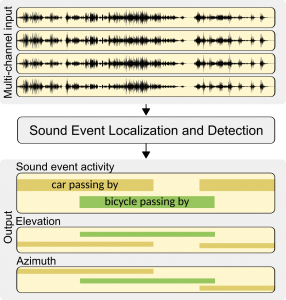 The goal of the sound event localization and detection task is to recognize individual sound events of specific classes, detect their temporal activity and estimate their location during the activity [3]. The main challenges in the task are the interfering directional events not belonging to the target classes, as well as spatial ambient noise always present in the acoustic environment. Input to the SELD system is multi-channel audio, captured with a microphone array, and the system output is the estimated sound event activity together with the spatial location of the event (elevation and azimuth). The task uses simulated scene recordings with dynamically moving target sound sources and interfering sound sources. The recordings are generated with isolated sound event samples and real measured room impulse responses.
The goal of the sound event localization and detection task is to recognize individual sound events of specific classes, detect their temporal activity and estimate their location during the activity [3]. The main challenges in the task are the interfering directional events not belonging to the target classes, as well as spatial ambient noise always present in the acoustic environment. Input to the SELD system is multi-channel audio, captured with a microphone array, and the system output is the estimated sound event activity together with the spatial location of the event (elevation and azimuth). The task uses simulated scene recordings with dynamically moving target sound sources and interfering sound sources. The recordings are generated with isolated sound event samples and real measured room impulse responses.
The SELD task is a relatively new research topic, and it has been part of the DCASE Challenge only in the three most recent editions. The difficulty of the task has been increased in each edition by making the setup more realistic. In the first edition (DCASE2019), the setup consisted of two static sound sources in the acoustic environment with low reverberation times. In the second edition (DCASE2020), the setup was made more challenging with increased reverberation times, added ambient noise, and dynamically moving sound sources. This year the complexity of the setup was increased further by having three moving sound sources and non-target sound sources in the scene. For system development, 10-hour annotated audio data in one-minute long scene recordings was provided and the challenge evaluation was done on 3 hours of audio data (one-minute recordings) without any metadata. In total there were 13 different simulated acoustic environments. The task received 36 system submissions from 12 international research teams. As the task setup has become more challenging over the years, the submitted solutions have moved from approaches doing separate sound event detection and localization towards joint architectures where sounds are localized and detected simultaneously. Currently, the best-performing systems are showing an impressive level of performance which is already suitable for some practical applications. Detailed results can be viewed on the task result page at the DCASE website.
 The goal of automatic audio captioning is to produce a textual description to describe the content of the audio segment [4]. It can be regarded as an intermodal translation task where input is an audio signal and the output is the textual description of the audio signal. Audio captioning methods can model different aspects of the content: sound attributes or concepts (e.g., “muffled sound”), properties of objects and environments (e.g., “big car passing by”), and high-level knowledge (e.g., “doorbell rings three times”).
The goal of automatic audio captioning is to produce a textual description to describe the content of the audio segment [4]. It can be regarded as an intermodal translation task where input is an audio signal and the output is the textual description of the audio signal. Audio captioning methods can model different aspects of the content: sound attributes or concepts (e.g., “muffled sound”), properties of objects and environments (e.g., “big car passing by”), and high-level knowledge (e.g., “doorbell rings three times”).
The captioning is a recent task in DCASE Challenge, organized for the second time in the DCASE2021 Challenge, partially supported by the MARVEL project. For system development, the Clotho dataset with almost 7000 samples (15-30 seconds long) with five different human-generated reference captions each was provided, and the challenge evaluation was done on over 1000 samples provided without any captions. The participants were allowed to use external data (data not provided through DCASE) as well when developing their systems. All submitted systems were substantially better performing than the provided baseline. Compared to DCASE2020, where the setup was the same, only the data amount was lower and external data was not allowed, the top performance increased by over 40%. Detailed results can be viewed on the results page at the DCASE website.
