Just-in-time decision making with deep neural networks

Almost everything we hear today about Artificial Intelligence has some connection to Deep Learning. Deep Learning refers to machine learning models which can receive as input raw (i.e., non-preprocessed) sensor data, such as audio signals, images, or videos, and provide in their output a decision. When they are used to perform classification, their decision takes the form of a probability-like vector, each element of which indicates how likely the input is to belong to one category, out of a predefined set of categories. A deep learning model is formed by multiple processing blocks which are connected in a hierarchical structure; the input of one block corresponds to the output of its preceding block. When the deep learning model takes the form of a neural network, these blocks commonly take the form of neural layers. A neural layer receives an input, which can be the input signal/image/video or the output of another neural layer, and performs a transformation to that input using a set of parameter values.
The power of deep neural networks comes from the process followed to estimate the parameter values of the neural layers through training. Deep neural networks are usually trained by following the end-to-end learning paradigm. This means that during training, the output of the deep neural network for a given input is compared against a target provided by a human expert. When the output is different from the target, the error is used to update the parameters of all neural layers forming the neural network in a combined manner. By doing this, each layer is trained to contribute to the final output in the best possible way.
However, the success of deep neural networks in classification problems comes with an increased number of parameters, which is the result of using multiple neural layers, each performing a high-dimensional transformation of its input. This leads to a high computational cost and creates restrictions in applications where decisions need to be taken close to the sensor, e.g. by using onboard processing (like embedded GPU platforms or mobile applications). Moreover, depending on the processing load of different processors, one may need to provide a classification response at a lower time interval compared to the time needed to process all the layers of the neural network to obtain its response. We refer to this problem as a just-in-time classification.
A common practice for achieving just-in-time classification for deep neural networks is to include in the neural network architecture multiple exit branches. An illustration of a deep neural network with early exit branches is shown in Figure 1. For deep neural networks trained by following the end-to-end learning paradigm, just-in-time classification is a challenging problem. This is due to the fact that the training of the neural network assumes that the parameters of all layers are jointly optimized and, thus, the best response can be obtained by using all the layers. MARVEL partners came up with ways to improve the performance of deep neural networks in just-in-time classification by proposing specially designed early exit branches [1] and improving their training process [2].
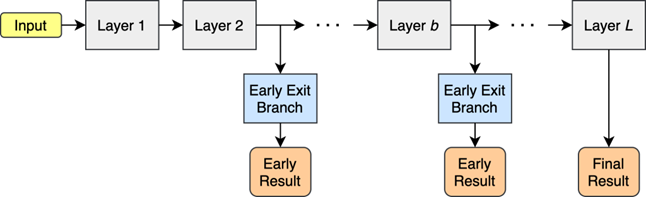
In the first approach [1], the layers of the early exit branches are designed to combine the information from all locations of the input. This way, optimizing the parameters of the early exit branch attached to any layer of the neural network can lead to increased performance because patterns in the entire input are combined in an optimized manner (learned through training). The second approach [2] uses the idea of curriculum learning. Curriculum learning defines strategies for training the parameters of the neural layers inspired by how humans learn: in the beginning, training is done by introducing to the neural network simple inputs in a similar manner as a teacher teaches a subject by introducing the simplest topics at the beginning of a lesson. As the training process progresses, the level of difficulty of the samples introduced to the neural layers is increased, similar to the way a teacher introduces more complex concepts which are easier to understand for the students who have prior knowledge of the simpler notions they learned at the beginning of their training. Following these approaches, high-performing early exit branches are obtained, improving the performance of such deep neural networks used in the MARVEL AI subsystem.
References
-
A. Bakhtiarnia, Q. Zhang and A. Iosifidis, “Single-Layer Vision Transformers for More Accurate Early Exits with Less Overhead”, arXiv:2105.09121v2, 2022
[1]
-
A. Bakhtiarnia, Q. Zhang and A. Iosifidis, “Improving the Accuracy of Early Exits in Multi-Exit Architectures via Curriculum Learning”, International Joint Conference on Neural Networks, 2021
[2]
Blog signed by: the AU team
Menu
- Home
- About
- Experimentation
- Knowledge Hub
- ContactResults
- News & Events
- Contact
Funding

This project has received funding from the European Union’s Horizon 2020 Research and Innovation program under grant agreement No 957337. The website reflects only the view of the author(s) and the Commission is not responsible for any use that may be made of the information it contains.