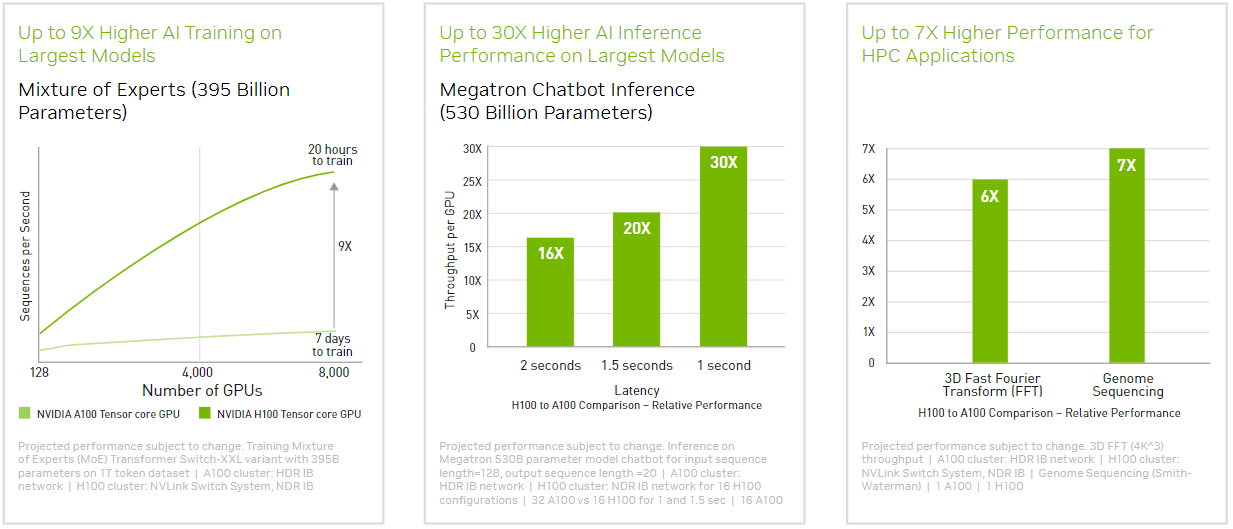
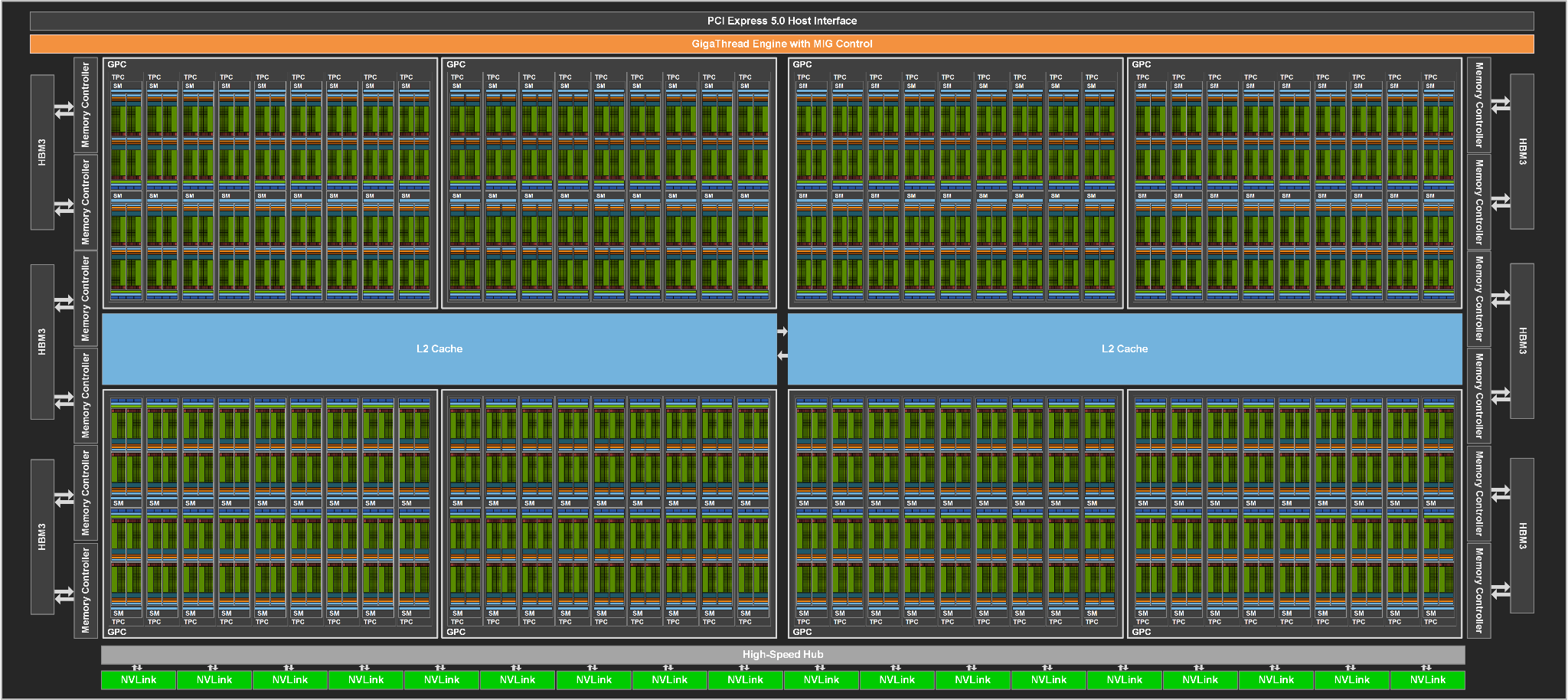
This website uses Google Analytics to collect anonymous information such as the number of visitors to the site, and the most popular pages.
Keeping this cookie enabled helps us to improve our website.
Please enable Strictly Necessary Cookies first so that we can save your preferences!