
Advanced MEMS microphones
Collect high-quality acoustic data for speech recognition, audio recording, and noise cancellation.
GRNEdge
Synchronize data streams for smart cities using a plug-and-play sensor.

AVDrone
System that classifies crowd behavior while ensuring user privacy.

AVRegistry
Store and access metadata of MARVEL Audio-Visual sources using a RESTful API compliant with Smart Data Models standard.

sensMiner
SensMiner Android app records and annotates environmental acoustics.

EdgeSec-VPN
System that classifies crowd behavior with privacy.

EdgeSec-TEE
EdgeSec TEE ensures confidential computing for Python apps that process sensitive user data using Trusted Execution Environments.

VideoAnony
VideoAnony component detects faces and number plates, and performs anonymization to simplify surveillance camera data analysis in public spaces.

AudioAnony
AudioAnony component anonymizes audio streams by replacing speaker voices with preserved speech features and environmental background.
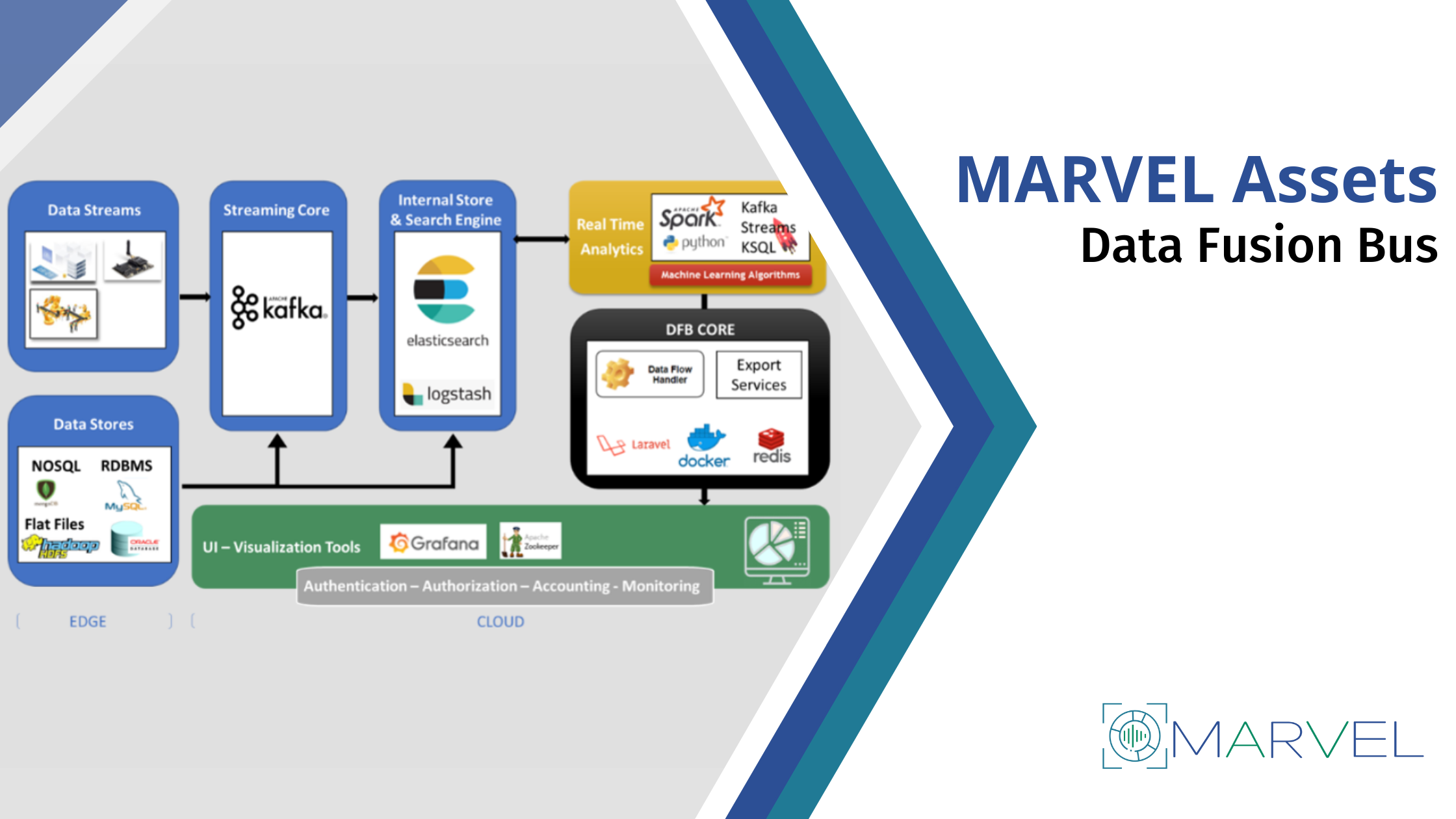
Data Fusion Bus
The Data Fusion Bus (DFB) allows efficient and trustworthy transfer of heterogeneous data between connected components and permanent storage.

StreamHandler
StreamHandler is a powerful distributed streaming platform based on Apache Kafka, designed for big data applications. It provides high performance, interoperability, resilience, scalability, and security.

DatAna
DatAna is a versatile platform that allows for scalable acquisition, transformation, and communication of streaming data across different layers of computing.

Hierarchical Data Distribution (HDD)
HDD (High-speed Distributed Data) is a software component that optimizes the topic partitioning process in Apache Kafka, a popular distributed streaming platform.

CATFlow
CATFLOW is a powerful tool for anonymizing road camera data and presenting it in a user-friendly dashboard.

devAIce
devAIce SDK is a powerful software development kit designed to help customers implement advanced audio analytics on their local premises.

Visual Anomaly Detection
Visual Anomaly Detection is an advanced tool that utilizes cutting-edge deep learning models to detect abnormal events in video streams with high accuracy.
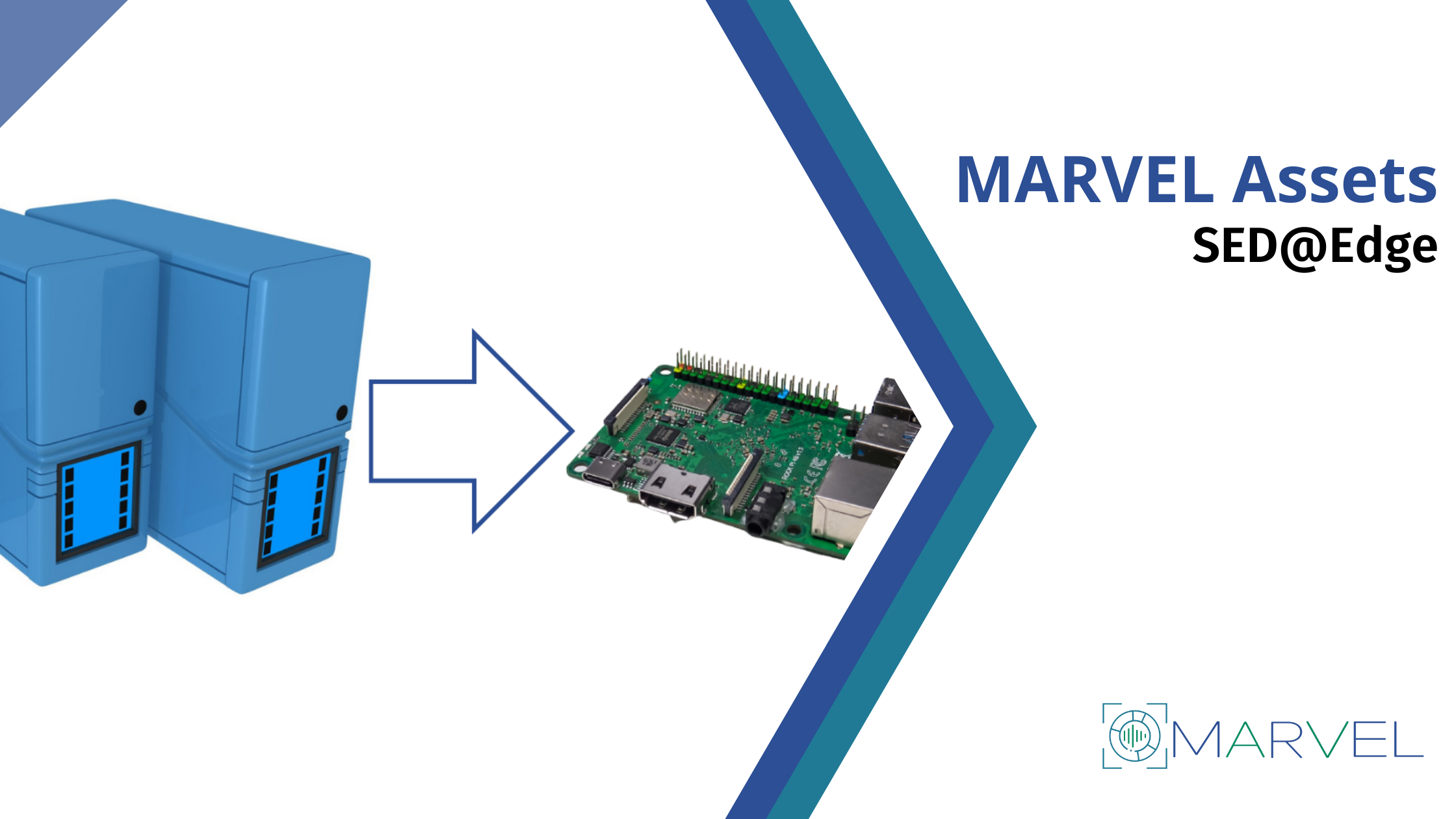
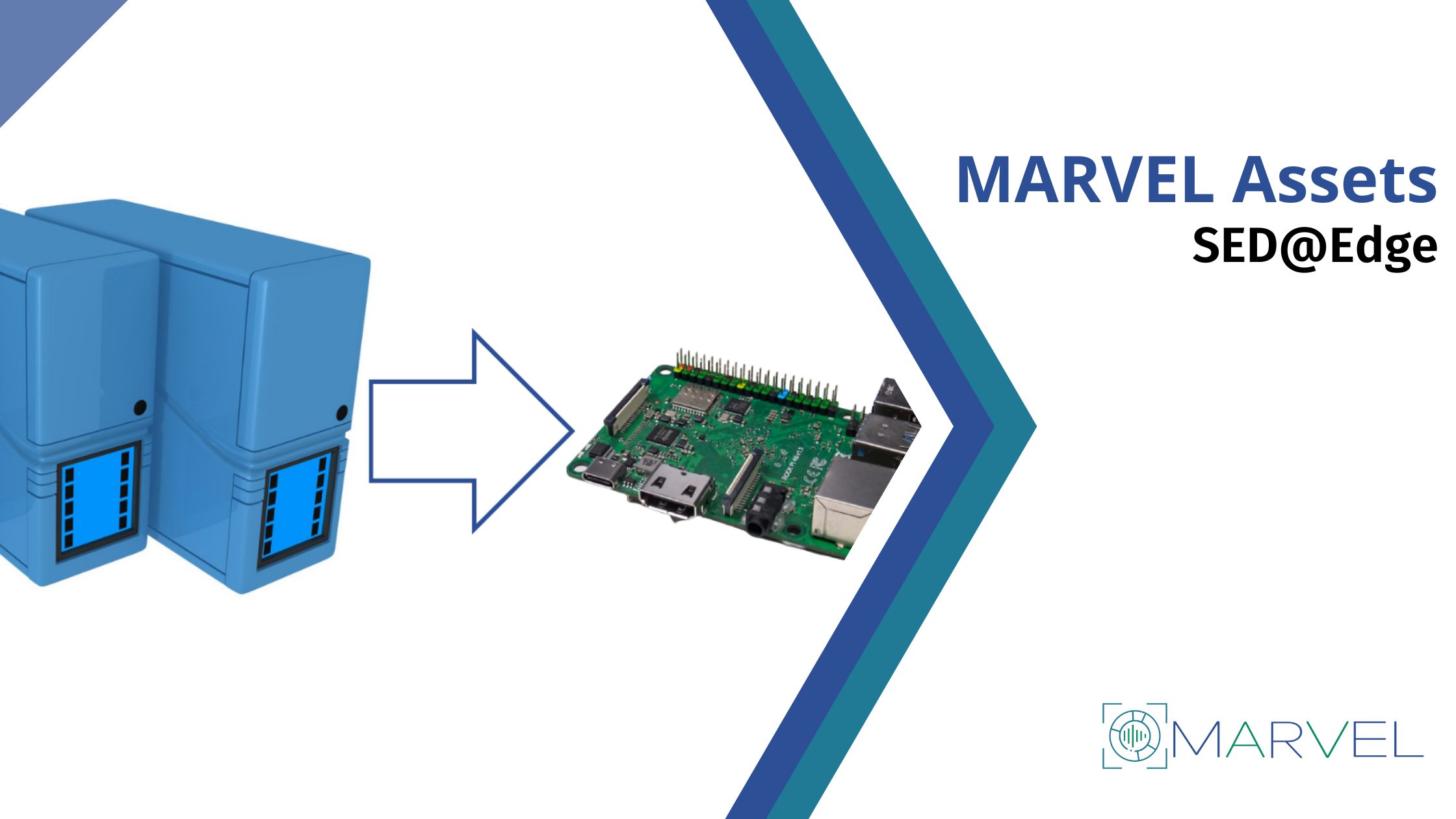
SED@Edge
SED@Edge is an innovative solution that enables the detection of urban acoustic events using deep learning models on low-cost, low-power microcontrollers with limited computational capabilities.

Audio-Visual Anomaly Detection
Audio-Visual Anomaly Detection is a powerful component for detecting abnormal events in multimodal streams.

Visual Crowd Counting
The VCC uses computer vision and deep learning techniques to accurately count and classify vehicles passing through a given area.

Audio-Visual Crowd Counting
The AVCC (Audio-Visual Crowd Counting) component is a solution for counting the number of people in a crowd from audio-visual data.

Automated Audio Captioning
The MARVEL Dashboard provides an intuitive interface that allows users to visualize and interact with the data generated by audio captioning systems.

Sound Event Detection
The VCC uses computer vision and deep learning techniques to accurately count and classify vehicles passing through a given area.

Sound Event Localisation and Detection
SELD component is a state-of-the-art method for sound event localization and detection.

GPURegex
FORTH platform includes a real-time stream processing engine designed to handle large volumes of data in real-time.

DynHP
DynHP, short for Dynamic Headroom Management, is a software solution that optimizes the use of computing resources in edge devices that have limited capabilities.
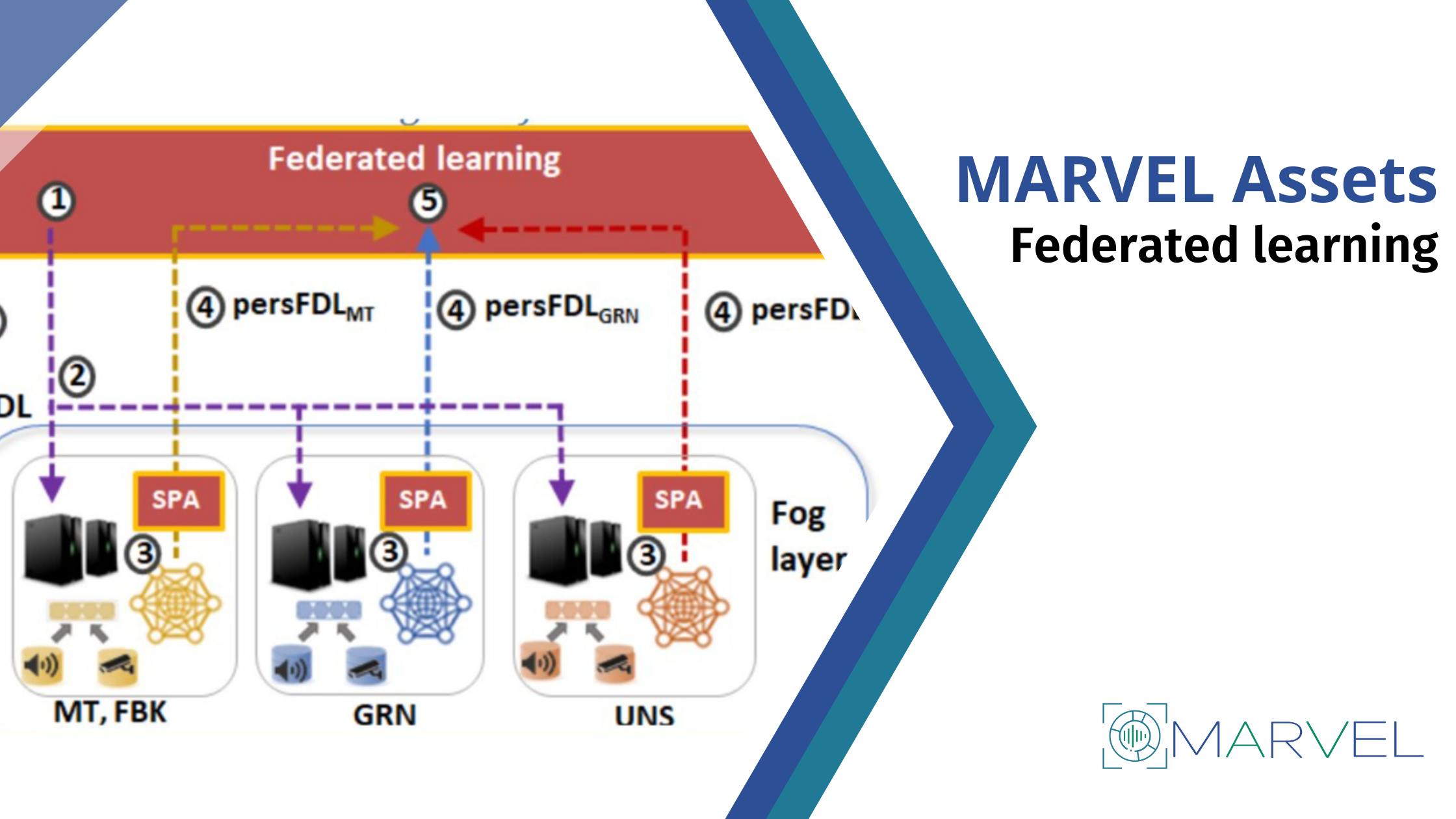
Federated learning
Federated learning is a distributed machine learning approach that allows multiple clients to collaboratively train a shared model while keeping their data private.

MARVdash
MARVdash is a platform that provides a web-based environment for data science in Kubernetes-based environments.

MARVEL Data Corpus-as-a-Service
MARVEL corpus has the potential to create significant impact on both SMEs and the international scientific and research community. By providing access to these data assets, SMEs and startups can test and build innovative applications, potentially creating new business opportunities.

Audio tagging
AT component in MARVEL implements a state-of-the-art method for audio tagging, which is used to analyze continuous audio streams and recognize active sound classes in the stream.